芯技术 | RISC-V的创新是在验证巨人的肩膀厚不厚实
[会员动态]
2022-11-21 17:45:49 编辑:yl
RISC-V又被称为“CPU的Linux”。对一些人来说,这个称谓像一种传承又像一种创新,尤其当你是开源的坚定信仰者。不过我是一个地道的实用主义者,而RISC-V的过度营销反而让我对这个词儿提不起兴趣。
直到我开始详细研究RISC-V,我才发现成为某种微处理器的Linux可能是RISC-V最不足为外人道的优点之一。
在以下的文章中,我将对RISC-V的创新性展开更深入的讨论。规范开源已经是许多框架都在做的事,所以并不新鲜,基于本身架构设计上的特性和开放性才让RISC-V的创新力凸显出来。
每个CPU都有一个指令集,那是一个所有可以执行的机器指令列表,可执行如两数相加,从内存中加载数据,或将其存储在内存中或跳转到程序中的另一个位置之类的操作。如今,大多数指令集架构都走增量进化路线,包括最热门的X86、MIPS、ARM。这意味着这些架构的创建者会随着时间的推移不断添加指令。但他们从不删除任何内容,也就造成了冗余无用的指令会堆积如山越来越多。And that’s why, X86有超过1500个不同的指令,ARM-64有1000多个。相比之下,RISC-V的诞生就是为了让冗余指令不再占用资源。让用来制作芯片的宝贵硅资源真正用到实处。怎么实现?RISC-V只有一个由47条指令组成的微小基本指令集。其它指令都作为扩展内容。每个扩展都是相关指令的集合。例如,SIMD 指令是一个扩展。浮点相关的指令是另一个。甚至整数乘法和除法也在单独的扩展中。RISC-V从一开始就建立了一个系统来管理这些扩展,按照A到Z26个字母排列。CPU中有一些特殊的bits,程序可以检查这些bits以查看实现了哪些扩展。如果一个程序忘记了管理系统并尝试运行特定RISC-V架构CPU不支持的指令,它仍然可以处理这个指令。不受支持的指令可能会导致陷阱。这类似于中断。当前位置被保存以供以后返回,并跳转到内核子程序。这允许RISC-V处理器在软件中实现它们不支持的每个扩展。因此,当某些扩展不再使用时,旧代码仍然可以在新CPU上运行。
理论上,英特尔和ARM可以辩称许多冗余指令已被弃用,要用需要在软件中再模拟。也能说新指令是某些可选扩展的一部分。但问题是:ISA就像一份合同。RISC-V基金会不会制造任何芯片或产品,他们做的就是制定规范。该规范就像注册RISC-V生态系统,即软件工具制造商、软件开发人员和硬件芯片制造商之间之间的合同。这些人同意遵守 RISC-V 规范。没有人会拿枪指着他们的头,或者如果他们不遵守这个“合同”,就会在法庭上威胁要处以罚款。那么,如何让参与者遵守合同呢?
因为利益。如果软件开发人员和硬件开发人员知道对方正确遵循规范,他们就知道他们的产品可以正常工作。硬件制造商不想制造无法运行RISC-V代码的芯片。软件开发人员也不想发布无法在RISC-V处理器上运行的代码。与ARM和x86不同,RISC-V 已经制定了一套程序,以确保软件和硬件具备处理不同扩展的兼容性。硬件提供了查询扩展是否存在的方法,如果遇到非法指令,可能会触发陷阱。
软件开发人员确保在需要时添加软件来模拟不受支持的指令。或者,编译器编写者可以确保根据支持的扩展为程序生成不同的代码。具体来说,这意味着生成子程序,这些子程序都使用不同的扩展名执行相同的操作。编译器创建所有这些子程序,并确保存在代码检查支持的扩展,然后再跳转到最佳子程序。简单举例。假设您得到了两个数组矢量加法,每个数组有三个元素。sum = [3, 4, 1] + [2, 1, 2] 编译器可以创建此代码的两个版本。一个基础指令集与循环一起使用,执行重复添加。另一个版本可以基于RISC-V矢量指令,不需要任何循环。您只需指定每个元素都是一个整数,每个矢量是3个元素。接下来,在矢量之间执行加法。在这两种情况下,您都会得到相同的结果,但是使用矢量指令扩展可以大大提高速度。
世界上已经充满了ARM和x86代码,但它们不检查扩展。因此,英特尔不能简单地停止在未来的微芯片中支持某些指令,因为现有软件将无法优雅地get到这一点。处理的过程会让它崩溃。RISC-V能做的事放在x86和ARM上将不得不以一种笨拙的方式举步维艰。此外,每个平台上都必须毫无意义地支持超过1000条指令。这就是RISC-V未来可期的原因。微架构的创新可能会使现有指令过时并需要一组新的指令,这对于RISC-V来说将很容易。他们为新的指示留下了足够的空间。相比之下,英特尔和ARM无法轻易做到这一点。
指令集的精简性往往会被严重低估。人们往往更容易对RISC-V吹毛求疵。
实际上,RISC-V中的所有功能从1980年代就有了,都是非常古老的想法。RISC-V规范的推出只是采用了旧有想法:加载/存储架构,大量寄存器,简单的指令编码,在指令中分离目标字段,并抛弃了一些糟粕。
然而,沿用旧有想法并非因为RISC-V设计人员缺乏想象力或创新失败。相反,他们刻意希望使用来自现有架构的经过验证的指令和设计。
原因很多。比如过去许多新颖且过于“聪明”的选择在未来的微架构创新中已过时。
相反,RISC-V的创新是取一切精华去一切糟粕的完美体现,以保证指令集的精简性。从过往经验中吸取的教训让他们知道将来需要同时支持压缩指令和64位指令。
RISC-V指令编码的变体很少,
这使得它们非常容易解码。
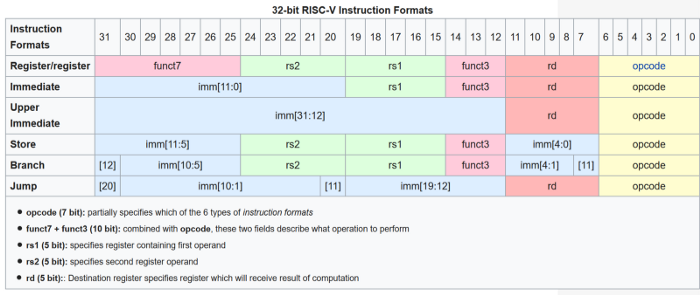
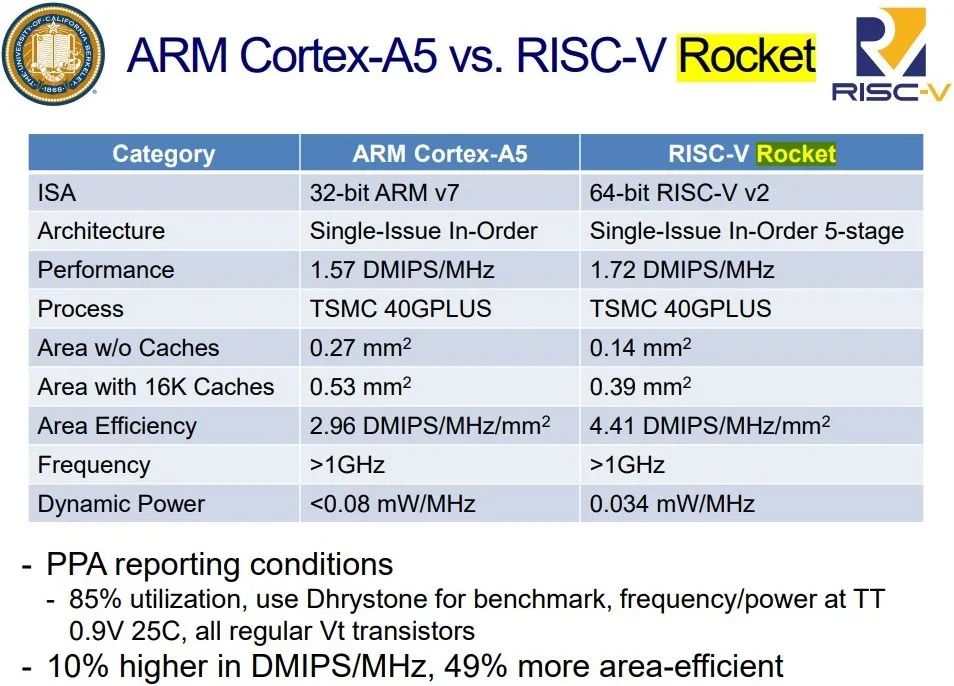
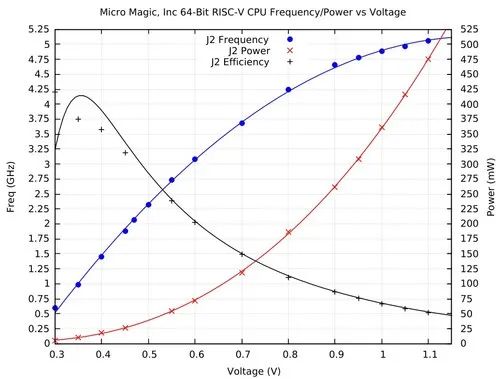
因此,RISC-V指令的编码都非常精细。上图显示了它们的编码方式。下面我们试着解释它的含义和意义。一个RISC-V指令的长度为32 bits,在所有RISC-V架构中都很常见。MIPS、PowerPC和ARM都是相同的。相较之下,x86倒有从8到120位的可变指令长度。一个bit只是二进制数中的一个数字。RISC-V指令中的前七个bits会指定要执行的指令(图中的黄色区)。操作码是要执行的操作,如加、减、乘、移位或跳转到程序中的其它位置。在红色区中,我们有目标寄存器(编号7到11位共五位)。这五位足以对从0到31的数字进行编码。因此,目标寄存器可以是32个不同的寄存器之一。省去细说步骤,懂得都懂。重点在于规范性的体现。对于各种变体编码都位于同一位置,这使得创建硬件解码RISC-V指令变得容易。精简性意味着晶体管尺寸会变少。RISC-V手册就是一个绝佳范例:作为简单性影响的一个具体例子,我们将“Demo级”RISC-V开源项目Rocket-chip处理器与使用相同大小的缓存(16 KiB)的相同技术(TSMC40GPLUS)中的ARM-32 Cortex-A5处理器进行比较。对于 ARM-32,RISC-V 的晶片尺寸为 0.27 mm2,精度为 0.53 mm2。ARM-32 Cortex-A5芯片的成本大约是RISC-V Rocket-chip片的两倍(22)。即使模具小10%,成本也可降低1.2倍(1.12)。其次,精简性有利于性能,因为更小和更简单的芯片更容易提高时钟频率。一家名为Micro Magic的小公司已经制造了一种RISC-V芯片,它可以在0.07w的功率上运行。

相比之下,苹果M1芯片在10w的功率上运行。Micro Magic芯片的时钟频率最高可达5 GHz。
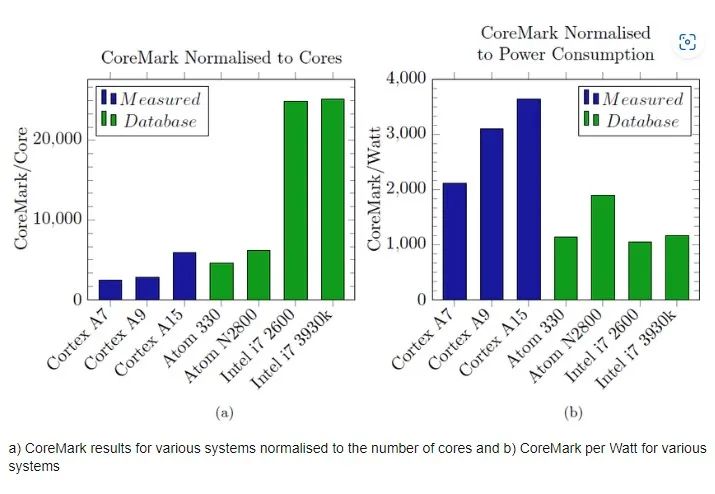
基于RISC-V的BOOM项目更足为人道。我们可以和ARM-32 Cortex-A9作比较。CoreMark是用来衡量嵌入式系统中CPU性能的标准。当两个处理器都在此基准测试上运行100 000次迭代(重复)时,ARM CPU 在 18.5 秒内完成,BOOM 处理器只需14.26 秒。这就证明了更简单的实现允许更高的时钟频率。讽刺的是,尽管指令集更简单,但ARM CPU在指令数量上并不具有优势。与ARM版本相比,CoreMark测试套件所需的指令数减少了10%。使用小型芯片还可以制作大量芯片来处理高度可并行的任务。例如,Esperanto Technologies公司就制作了一个具有1000多个RISC-V协处理器的片上系统用于机器学习任务。
乍看之下“凝练”这个词不该用来形容RISC-V。但实际上,压缩指令集和64 bits指令等从一开始就被预设具有可扩展性。基本指令级是在设计时考虑到将有一个64 bits扩展,而这一点之前的设计都没有考虑到,所以32 bits指令都必须为64 bits的重复。相较之下,在RISC-V上大多数现有指令只在64 bits寄存器上工作,而不是在64 bits的RISC-V CPU上使用32 bits寄存器。因此,RISC-V 64 bits扩展实际上只是添加特殊指令来处理64 bits寄存器的32 bits部分。
例如, ADDW 和 SUBW 指令用于将32 bits结果存储在目标寄存器中。正常 ADD 和 SUB 指令会在 64 bits CPU 上加减 64 位数字,在32 bits CPU 上加减32 bits的数字。
这意味着RISC-V上的64 bits 的代码看起来几乎与32 bits 代码相同。
压缩指令集是一个类似的扩展指令集,允许将两个指令放在32 bits 字节内,而其它框架只能用笨拙的方式挤压。例如,在ARM上Thumb2 压缩指令格式本质上是一种不同的ISA,而不是RISC-V上的扩展。这意味着CPU必须在内部切换模式并使用不同的解码器。这增加了复杂性。相比之下,解码压缩的RISC-V指令非常简单。将它们转换为32位指令只需要400个逻辑门(与门、或门、或非门、与非门)。这还只是冰山一角。
实现基本指令集的最小RISC-V CPU仅用了8000个逻辑门。
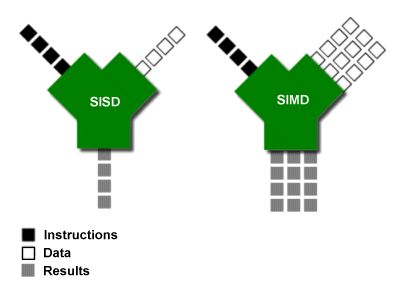
虽然这不是RISC-V独有的,但RISC-V指令集的特性绝对可以证明经验验证的后发优势。当其它CPU不断添加一个接一个的SIMD指令,而每次决定延长SIMD指令的操作时间时,都需要一组新的指令。相比之下,使用RISC-V,CPU可以在运行时通知代码它支持什么,并允许程序员自己指定矢量的长度。这大大简化了矢量代码。矢量指令集实际上是一种陈旧且更易于理解的技术,编译器优化对此有很好的理解。例如,Esperanto Technologies在其基于RISC-V的专用协处理器中使用矢量指令集来加速机器学习任务。他们声称性能比竞争对手高出30-50倍。
让我们看看我是否可以压缩我刚刚RISC-V创新性介绍中精简出一些内容:非增量ISA。以前添加的指令不会永远使ISA膨胀。软件开发人员、工具开发人员和硬件制造商必须确保可选扩展的存在与否是可控的。
积极删除严格来说不需要的所有内容,以将复杂性保持在最低限度。这意味着它很容易实现RISC-V芯片,并且可以在几个晶体管中完成,使其更便宜,更容易增加时钟频率等。
来源:酷芯微电子
作者:Erik Engheim
翻译:酷芯PR团队
校对:酷芯芯片工程部